
Welcome to Haomin Li(李皓民)’s Homepage~
I am now chasing my Ph.D. degree in CS. in Shanghai Jiao Tong University, Intelligent Memory & Processor Architecture & Computing Lab (IMPACT Lab), under the supervision of Prof. Li Jiang and Assist Prof. Fangxin Liu. I graduated from the College of Intelligence and Computing, Tianjin University with a bachelor’s degree in 2022.
My current research interests focus on Hardware-software Co-Design for Efficient and Secure AI.
Hardware: Domain Specific Architectures (DSAs), In-Memory Computing (CIM), Edge FPGAs, and Edge/Server GPUs.
Software: Brain-Inspired Neuromorphic Computing, LLMs/Neural Networks, Spatial Intelligence (Efficient 3D Perception and Reconstruction), and Secure AI Workloads.
🔬 Research Focus
- Brain-inspired Neuromorphic Computing:
- Effective Applications [ICCAD’23, SIGIR’22]
- Adaptive and Flexible Compression [ISCA’25, ASP-DAC’25]
- Execution Optimization [2×DATE’25, TPDS’24, ASP-DAC’24]
- CiM-based Accelration [APPT’25, MICRO’24, ASP-DAC’24]
- LLMs/Neural Network Acceleration
- Acceleration of Neural Networks via Efficient Encoding [HPCA’24, DAC’24, ICCAD’25]
- Sparsity Compilation [HPCA’25, TODAES’24, ASP-DAC’24]
- Spatial Intelligence (Efficient 3D Perception and Reconstruction)
- Deformable Attention Optimization for Efficient 3D Detection [DAC’24]
- 3D Reconstruction Acceleration [HPCA’26, ASPLOS’25]
- Efficient design for Secure AI
- Area Effcient Design for LUT-based Large Number Modular Reduction [DATE’26, DAC’25]
- Secure Neuromorphic Computing [DAC’24, ASP-DAC’24, DAC’23, TACO’25]
🔥News
- 2025.11: 🎉🎉 Our paper “ORANGE: Exploring Ockham’s Razor for Neural Rendering by Accelerating 3DGS on NPUs with GEMM-Friendly Blending and Balanced Workloads” about 3DGS Acceleration on NPUs has been accepted by HPCA 2026!
- 2025.11: 🎉🎉 Our paper “LaMoS: Enabling Efficient Large Number Modular Multiplication through SRAM-based CiM Acceleration” about CIM-based modular multiplication acceleration has been accepted by DATE 2026!
- 2025.07: 🎉🎉 Our paper “QUARK: Quantization-Enabled Circuit Sharing for Transformer Acceleration by Exploiting Common Patterns in Nonlinear Operations” about nonlinear operation approximation and acceleration has been accepted by ICCAD 2025!
- 2025.04: 🎉🎉 Our paper “ASDR: Exploiting Adaptive Sampling and Data Reuse for CIM-based Instant Neural Rendering” about CiM-based NeRF Acceleration has been accepted by ASPLOS 2025! We will present our paper in ASPLOS 2026~
- 2025.04: 🎉🎉 Our paper “Attack and Defense: Enhancing Robustness of Binary Hyper-Dimensional Computing” about bio-inspired model robustness exploration has been accepted by TACO!
- 2025.03: 🎉🎉 Our paper “FATE” about bio-inspired model acceleration has been accepted by ISCA 2025!
- 2025.02: 🎉🎉 Our paper “ALLMod” about large number modular reduction has been accepted by DAC 2025!
- 2024.11: 🎉🎉 Our paper “TAIL” and “HyperDyn” have been accepted by DATE 2025!
- 2024.09: 🎉🎉 Our paper “NeuronQuant” has been accepted by ASP-DAC 2025!
- 2024.08: 🎉🎉 Our paper “HyperFeel”, “PAAP-HD”, and “TEAS” have been accepted by ASP-DAC 2024!
- 2023.07: 🎉🎉 Our paper “HyperNode” has been accepted by ICCAD 2023! San Francisco Again ^_^!
- 2023.02: 🎉🎉 Our paper “HyperAttack” has been accepted by DAC 2023!
📝 Selected Publications
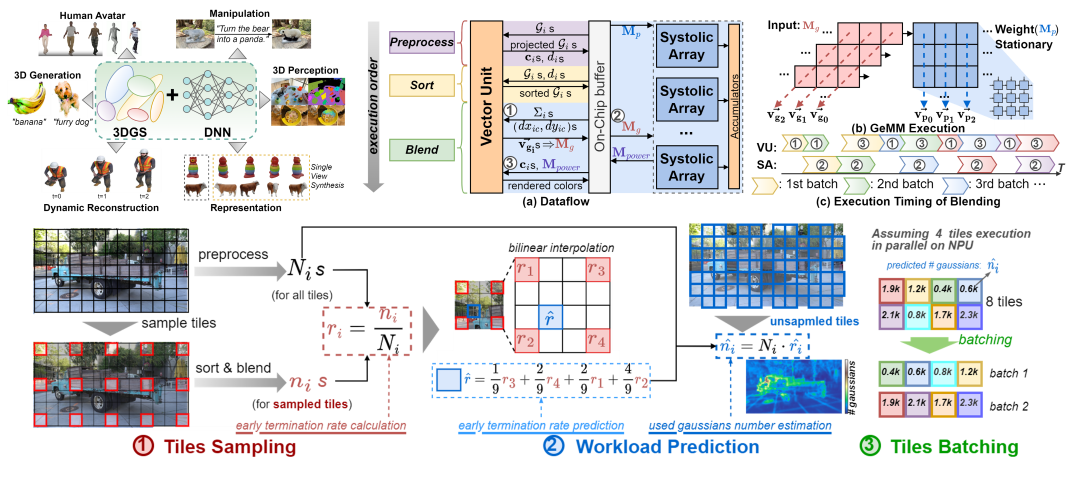
ORANGE: Exploring Ockham’s Razor for Neural Rendering by Accelerating 3DGS on NPUs with GEMM-Friendly Blending and Balanced Workloads
Haomin Li, Yue Liang, Fangxin Liu, Bowen Zhu, Zongwu Wang, Yu Feng, Liqiang Lu, Li Jiang, and Haibing Guan
Description: ORANGE is a novel approach that enables general purpose DNN-oriented Neural Processing Units (NPUs) to execute 3DGS without requiring specialized acclerators. Our approach offers a cost-effective and versatile solution, adhering to the principle of Ockham’s Razor by maximizing efficiency without specialized hardware.
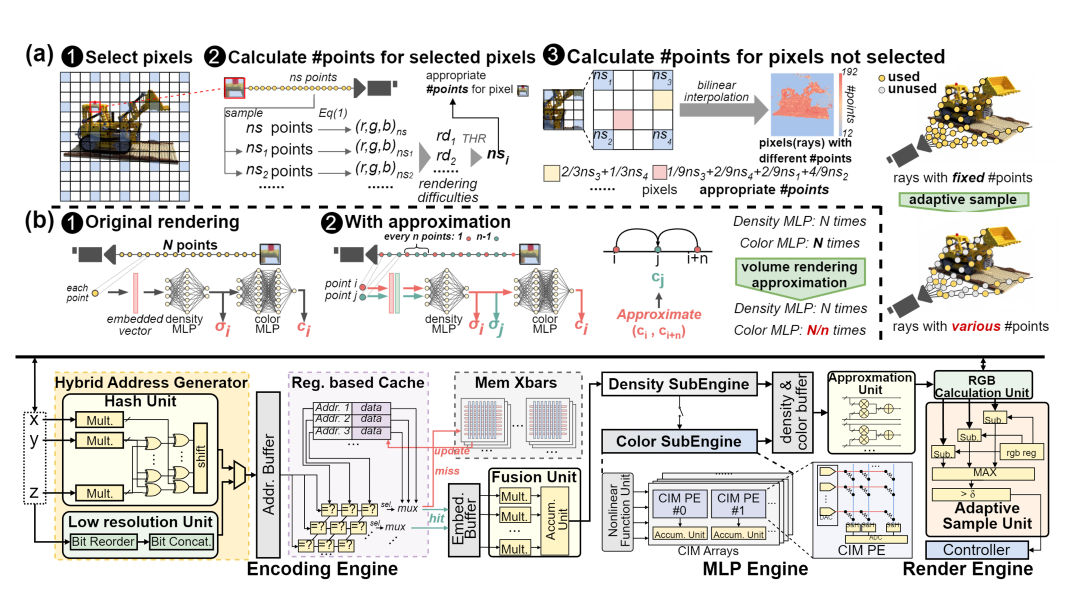
ASDR: Exploiting Adaptive Sampling and Data Reuse for CIM-based Instant Neural Rendering
Fangxin Liu=, Haomin Li=, Bowen Zhu, Zongwu Wang, Zhuoran Song, and Li Jiang
Description: ASDR is a CIM-based accelerator supporting efficient neural rendering. At the algorithmic level, we propose two rendering optimization schemes: (1) Dynamic sampling by online sensing of the rendering difficulty of different pixels, thus reducing access memory and computational overhead. (2) Reducing MLP overhead by decoupling and approximating the volume rendering of color and density. At the architecture level, we design an efficient ReRAM-based CIM architecture with efficient data mapping and reuse microarchitecture.
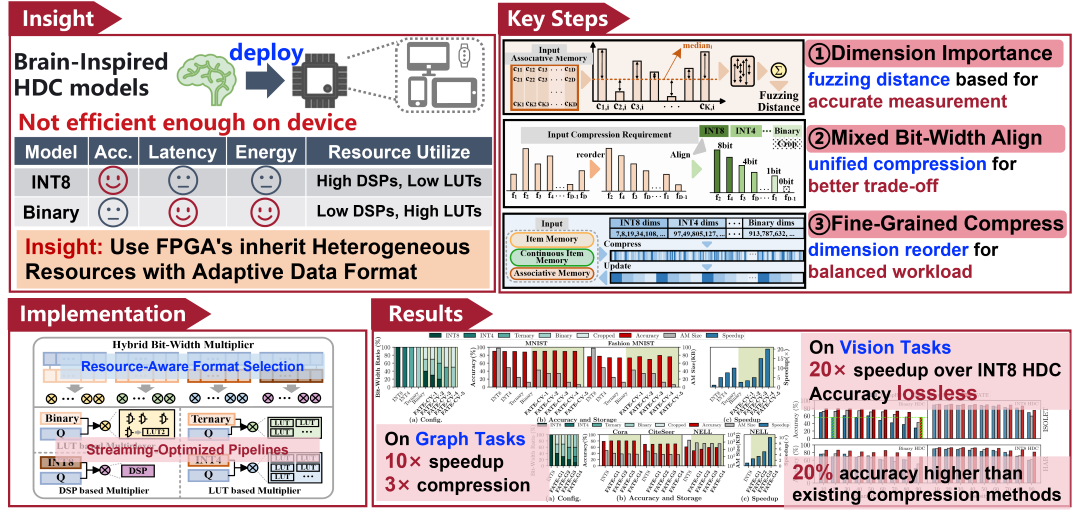
FATE: Boosting the Performance of Hyper-Dimensional Computing Intelligence with Flexible Numerical DAta TypE
Haomin Li, Fangxin Liu, Yichi Chen, Zongwu Wang, Shiyuan Huang, Ning Yang, Dongxu Lyu, and Li Jiang
Description: FATE is an algorithm/architecture co-designed solution for brain-inspired Hyper-Dimensional Computing (HDC) deployment, which utilizes low-precision data types for less important dimensions, enabling the replacement of multiplication operations with logic calculations. To maximize resource utilization, we design a workload-aware mixed quantization scheme that offers flexible compression based on these differences in dimensional importance. The proposed quantization framework is seamlessly integrated into the existing FPGA implementations.
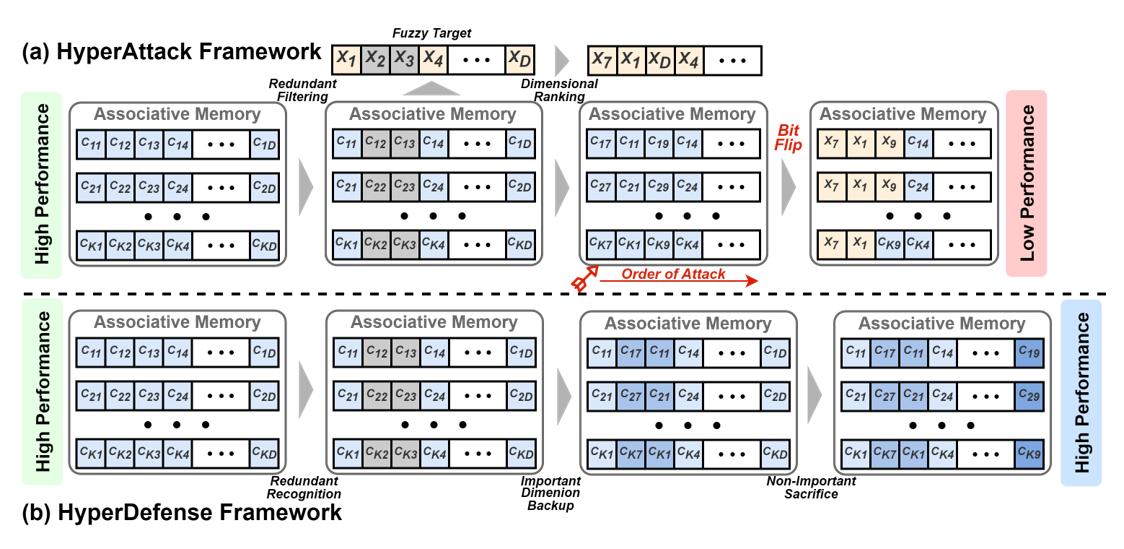
Attack and Defense: Enhancing Robustness of Binary Hyper-Dimensional Computing
Haomin Li, Fangxin Liu, Zongwu Wang, Ning Yang, Shiyuan Huang, Xiaoyao Liang, and Li Jiang
Description:
Hyper-Dimensional Computing (HDC) has emerged as a lightweight computational model, renowned for its robust and efficient learning capabilities, particularly suitable for resource-constrained hardware. As HDC often finds its application in edge devices, the associated security challenges pose a critical concern that cannot be ignored. In this work, we aim to quantitatively delve into the robustness of binary HDC, which is widely recognized for its robustness. Employing the bit-flip attack as our initial focal point, we meticulously devise both an attack mechanism (HyperAttack) and a corresponding defense mechanism (HyperDefense). Our objective is to comprehensively explore the robustness of the binary hyper-dimensional computation model, aiming to gain a deeper understanding of its security vulnerabilities and potential defenses.
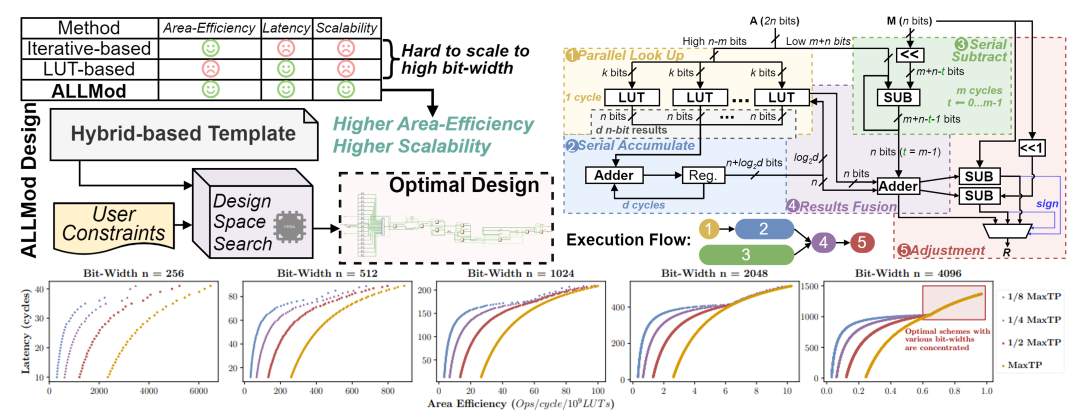
ALLMod: Exploring Area-Efficiency of LUT-based Large Number Modular Reduction via Hybrid Workloads
Fangxin Liu=, Haomin Li=, Zongwu Wang, Bo Zhang, Mingzhe Zhang, Shoumeng Yan, and Li Jiang
Description:
Modular reduction is widely used in cryptographic applications. High-bit-width operations are crucial for enhancing security; however, they are computationally intensive due to the large number of modular operations required. The LUT-based approach, a “space-for-time” technique, reduces computational load by segmenting the input number into smaller bit groups, pre-computing modular reduction results for each segment, and storing these results in LUTs. While effective, this method incurs significant hardware overhead due to extensive LUT usage. In this paper, we introduce ALLMod, a novel approach that improves the area efficiency of LUT-based largenumber modular reduction by employing hybrid workloads. Inspired by the iterative method, ALLMod splits the bit groups into two distinct workloads, achieving lower area costs without compromising throughput. We first develop a template to facilitate workload splitting and ensure balanced distribution. Then, we conduct design space exploration to evaluate the optimal timing for fusing workload results, enabling us to identify the most efficient design under specific constraints.